
Hackergame 2021 Personal Write-up
这是我个人的 write-up,仅包含我赛时会做的题(其它题看官方题解就好了,没必要再写一遍),记录自己做题时的奇奇怪怪的乱搞方法,仅供参考。
由于我只是个菜鸡,所以解题方法可能会有点绕,可能原理甚至有问题,请大佬原谅我这个菜鸡。
前言
谨以此文纪念我参加的第一场 Hackergame。
这次 Hackergame 感觉有比较多的乱搞题(然后才能让我这种乱搞选手能拿到可观的分数)。然后像是比较正经的 binary 题,我是差不多一个都不会做的(比赛结束前 1 天的时候,binary 还是 150)。
目录
没有链接样式的都是不会做的,或者是(对于有多个子问题的题目)没有完全做出来的。
- 签到
- 进制十六——参上
- 去吧!追寻自由的电波
- 猫咪问答 Pro Max
- 卖瓜
- 透明的文件
- 旅行照片
- FLAG 助力大红包
- Amnesia
- 轻度失忆
- 记忆清除
- 图之上的信息
- Easy RSA
- 加密的 U 盘
- 赛博厨房
- 灯,等灯等灯
- Level 0
- Level 1
- Level 2
- 只读文件系统
- 一石二鸟
- Micro World
- 卷王与野生的 GPA
- 阵列恢复大师
- 链上预言家
- 助记词
- Co-Program
- 马赛克
- minecRaft
- 密码生成器
- 外星人的音游掌机
- JUST BE FUN
- fzuu
- p😭q
- Make a wish
- 超 OI 的 Writeup 模拟器
签到
点按钮可以切换 Page,然后不同的 Page 对应不同时间。
并且可以观察到,Page 的 number 就是 Unix 时间戳。
我们不妨大胆猜想,把 Unix 时间戳设置成当前时间,即访问 http://202.38.93.111:10000/?page=1634968833,然后发现就可以获得 Flag。
进制十六——参上
观察到右边的 flag 被遮住了,但是左边的 hex 却没有被遮住。所以就可以解析左边的 hex 得到右边的 flag:
1 | codecs.decode( |
去吧!追寻自由的电波
下载音频,发现音频播放速度非常快,大概是被暴力压缩了。
我们可以随便找点软件(我用了手边的 iMovie),把音频放慢,就可以听了。
题目云「使用了无线电中惯用的方法来区分字符串中读音相近的字母」,即 e 用 echo 表示,等。 虽然英语听力不太行,但是听首字母还是能勉强听得出来的。
小彩蛋(?):把音频放的没那么慢,可以听到女声;再放慢点,就变成了男声,这就说明……(逃)
猫咪问答 Pro Max
- 2017 年,中科大信息安全俱乐部(SEC@USTC)并入中科大 Linux 用户协会(USTCLUG)。目前,信息安全俱乐部的域名(sec.ustc.edu.cn)已经无法访问,但你能找到信息安全俱乐部的社团章程在哪一天的会员代表大会上通过的吗?
提示:输入格式为 YYYYMMDD,如 20211023。请不要回答 “能” 或者 “不能”。
看到「已经无法访问」,直接下意识想到 web.archive.org。
在 web archive 里打开 sec.ustc.edu.cn,找到章程,然后就找到其通过日期为 2015 年 5 月 4 日。
- 中国科学技术大学 Linux 用户协会在近五年多少次被评为校五星级社团?
提示:是一个非负整数。
查资料无果(可能我姿势不对),先下一题。
- 中国科学技术大学 Linux 用户协会位于西区图书馆的活动室门口的牌子上“LUG @ USTC”下方的小字是?
提示:正确答案的长度为 27,注意大小写。
经过多次搜索尝试,在 Google 搜索 “LUG USTC” 并切换至“图片”一栏,就可以发现这么一张照片:

即 “Development Team of Library”,刚好是 27 个字。
- 在 SIGBOVIK 2021 的一篇关于二进制 Newcomb-Benford 定律的论文中,作者一共展示了多少个数据集对其理论结果进行验证?
提示:是一个非负整数。
搜索 “SIGBOVIK Newcomb-Benford”,然后就能找到一篇论文(集):SIGBOVIK 2021。
通过目录找到这篇文章,然后仔细阅读,并且与作者友善探讨学术问题(大雾)。
实际上通过简单提取,不难发现附录的 figures 都是数据集,一共有 14 - 1 = 13 个
- 不严格遵循协议规范的操作着实令人生厌,好在 IETF 于 2021 年成立了 Protocol Police 以监督并惩戒所有违背 RFC 文档的行为个体。假如你发现了某位同学可能违反了协议规范,根据 Protocol Police 相关文档中规定的举报方法,你应该将你的举报信发往何处?
正确答案的长度为 9。
搜索 “IETF Protocol Police”,不难找到 RFC 8962。
直接搜索关键词 (e)mail 或 send,不难找到「Send all your reports of possible violations and all tips about wrongdoing to /dev/null.」(不得不说,这个玩笑开得真是可以)。
所以答案就是 /dev/null,长度也刚好是 9。
(手动分割线)
然后至此我们找到了 1, 3, 4, 5 的答案,还剩下的第 2 题,可能的答案只有 6 种,手动枚举一下即可(居然是 5 次,我还以为是 0)。
卖瓜
说实话,我猜不出它(服务器 PHP 代码)是怎么算的,然后就搞不清楚具体是怎么溢出的,但是还是可以瞎试。
完了,我忘记我当时是怎么试的了。
Update:我想起来了。
首先,盲猜一下数值的范围是 263 以内,然后整 ⌊9263⌋+1(1024819115206086201)个 9 斤的瓜,这样乘一下恰好能超过范围。
提交一下,得到「电子秤上已有 -9223372036854775808/20 斤的瓜」。
再加上 1024819115206086200(比上面少 1)个瓜,就变成了「电子秤上已有 -8/20 斤的瓜」。
接下来再买 1 个 9 斤瓜,再买 1024819115206086201 个,再买 1024819115206086200 个,此时,就有:「电子秤上已有 -7/20 斤的瓜」。
此时再买上 3 个 9 斤瓜,就可以刚好到 20 斤,就「恭喜你逃过一劫!」。
上面的操作不能合并,不要问我为什么,我也不知道。我只是瞎试的。
透明的文件
打开文件,发现里面的字符好像 \033 控制符(然后就是缺了 \033)。不妨试试在 [ 前都加上 \033(据说 \033 后面一定会接着 [)。
然后打印之,可得:
![]()
不难读出,flag 是 flag{abxnniohkalmcowsayfiglet}。
附读取程序:
1 |
|
旅行照片
读题,发现题目的着重点在 KFC 上,并且其非常近海,猜想符合条件的 KFC 不多。
于是搜索 “海边 KFC”,虽然不能直接找到目标(大概?),但是过半的搜索结果都是关于“秦皇岛”的。
然后打开地图,定位到秦皇岛,查找附近的 KFC,得:
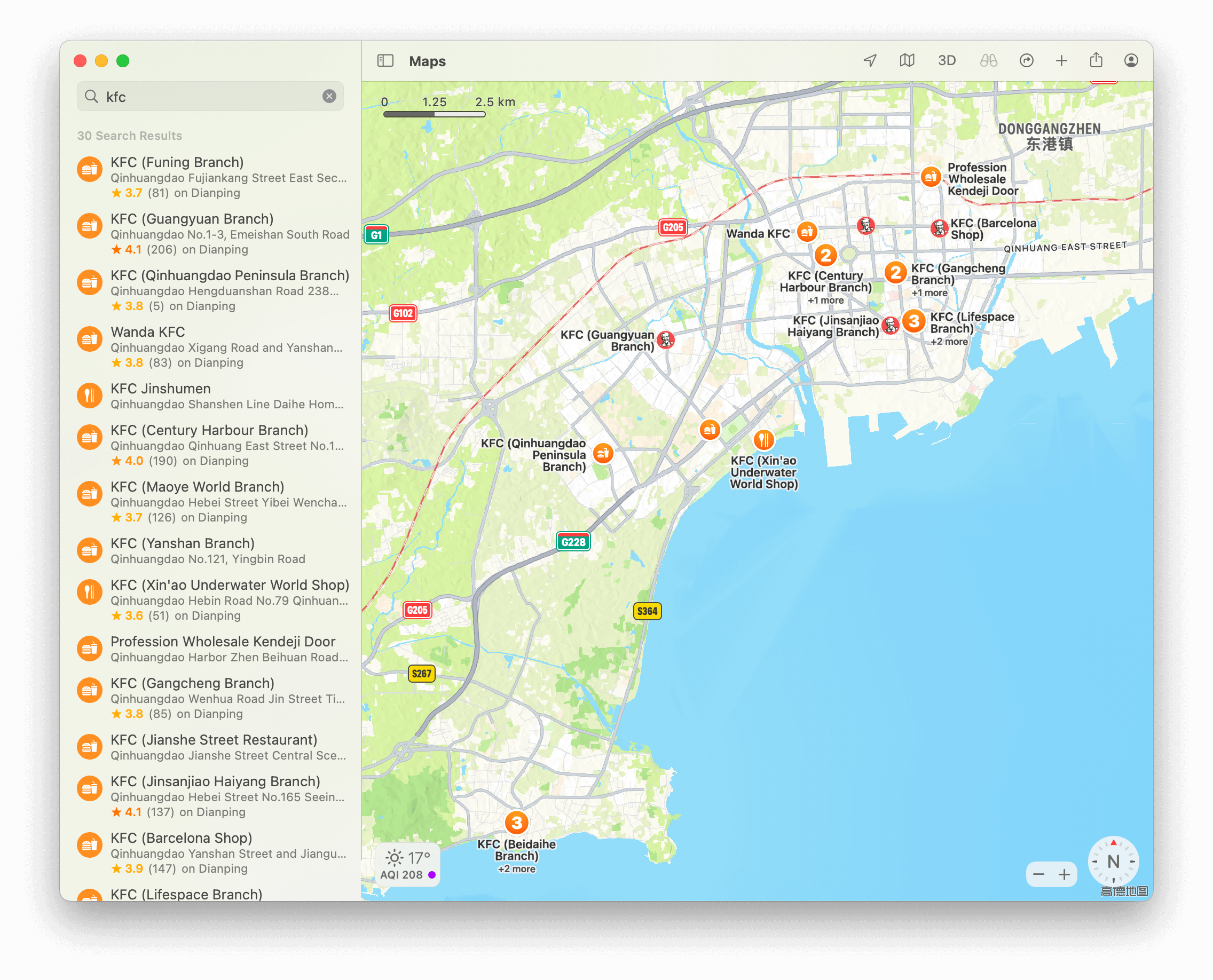
发现有一家 KFC 很接近海,打开卫星图模式,并放大观察:
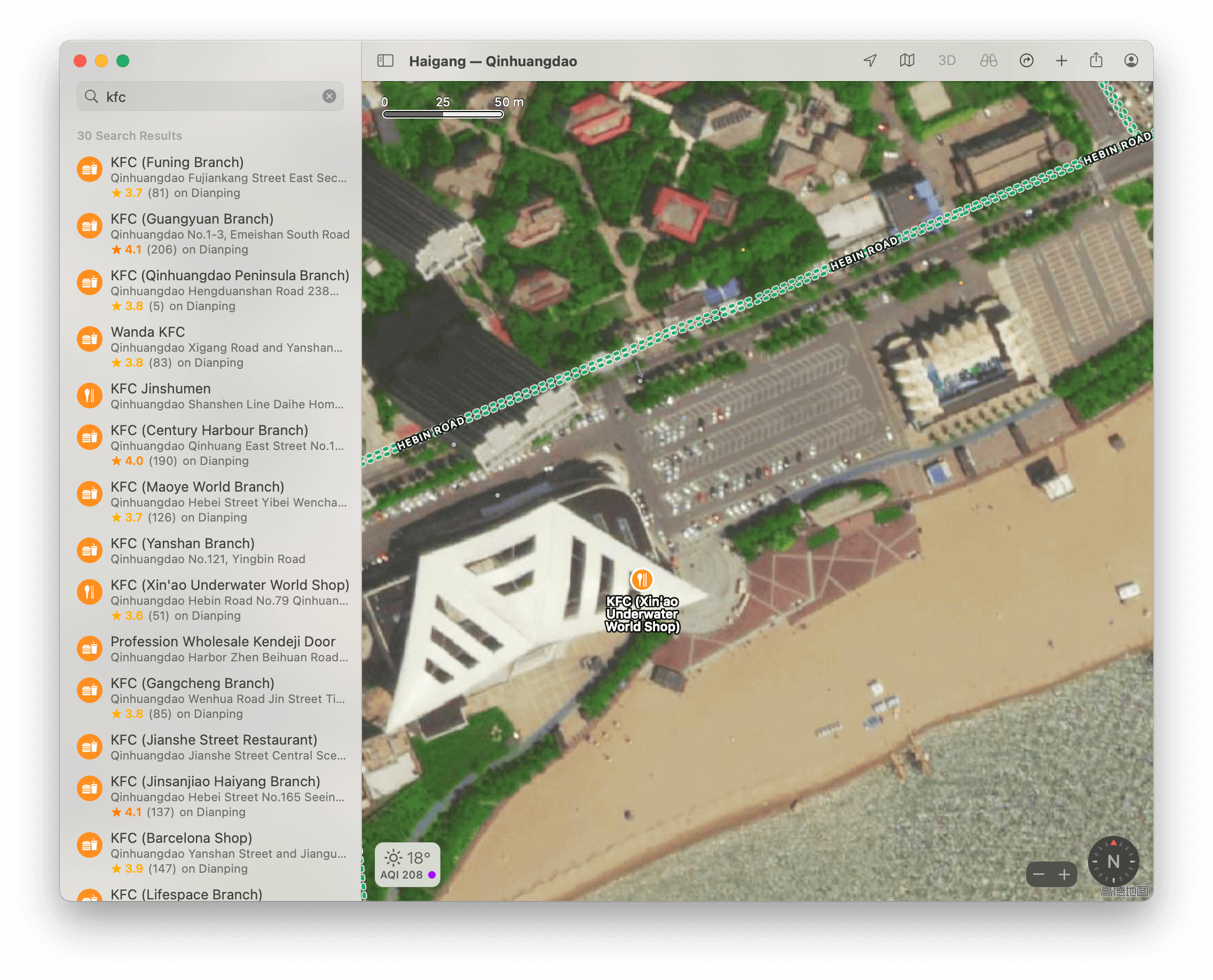
可以发现停车位对上了,那块覆盖着植被的石头也对上了,虽然 KFC 位置出现了一点偏差,但是不影响做题。
观察原图的停车位方向和阴影方向,不难发现拍摄者面朝东南,时间是傍晚。
然后打开百度街景(不是广告),观察实地景象。百度街景这都多久没更新了?
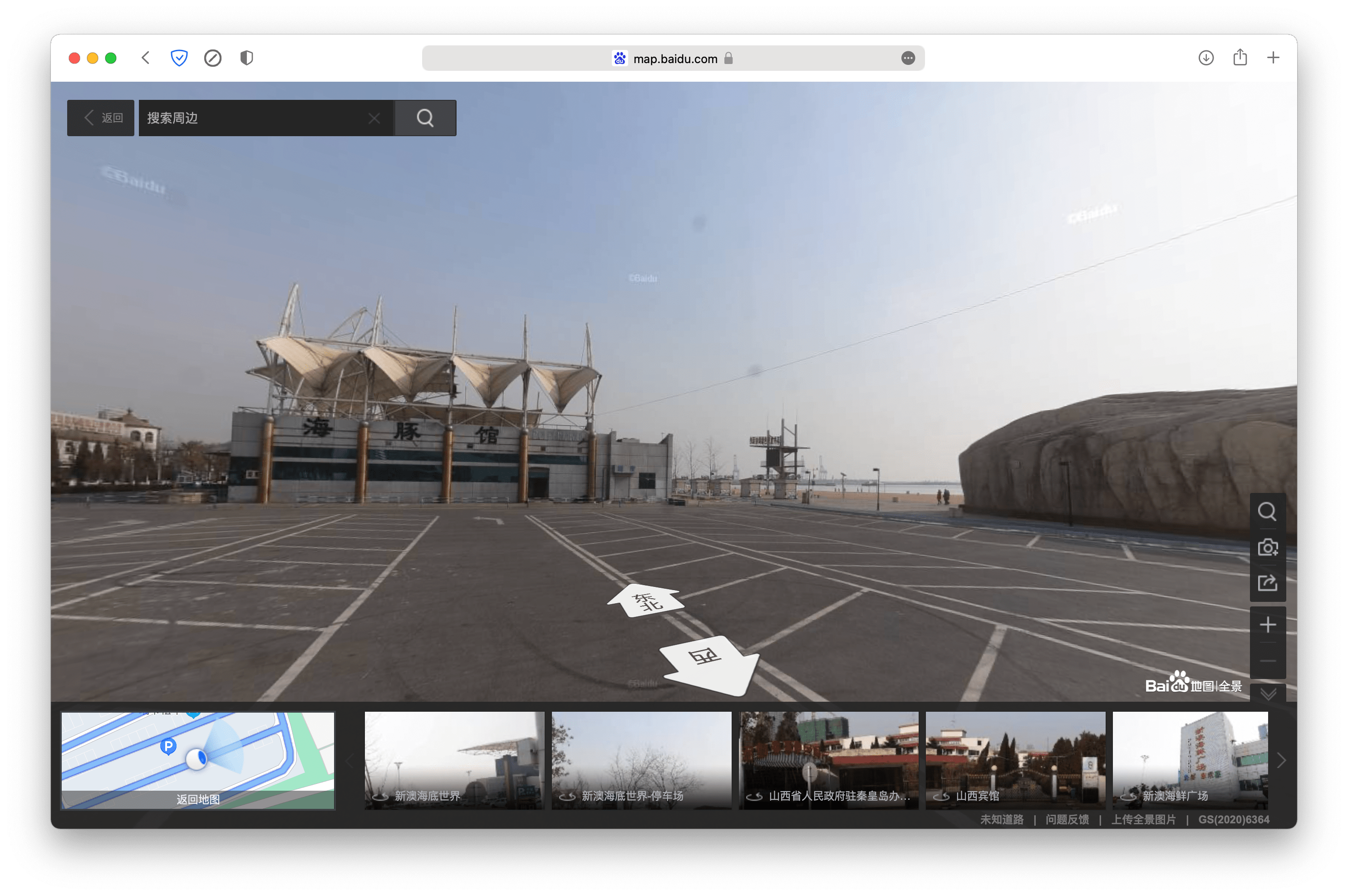
虽然没有 KFC,但观察屋顶,还是能确定就是那里的。然后就能确定那三个大字就是「海豚馆」。
然后打开 KFC 门店信息查询,定位秦皇岛。
虽然「新澳海底世界甜品餐厅」没有电话,猜测电话跟旁边的「新澳海底世界餐厅餐厅」一样(0335-7168800)。
最后还剩下楼层高度,看隔壁楼层数一下,大概是在 14 层左右(如果不对就上下多试几层就对了)。
FLAG 助力大红包
总结题意:你需要用 256 个不同的 /8 IP 地址砍红包(访问对应 URL)。
但是这怎么可能呢,有些 IP 段本来就是有保留用途的,而且时间还限制 10 分钟。
经过一番胡思乱想,发现可以通过携带 X-Forwarded-For header 来欺骗,就能轻松砍到 flag。
1 | import requests |
Amnesia - 轻度失忆
.data 段没了,字符串常量是储存在这里的。既然不能用字符串常量,就分割成字符就可以了。
1 |
|
图之上的信息
经过简单尝试(瞎改原请求的参数,然后看错误信息),可以知道 GraphQL 里面有 GUser 类型,其中有 id, username 两个字段。
查 GraphQL 文档,找到“内省”部分,可以用如下代码获取 GUser 的所有字段:
1 | { "query": "{ __type(name: \"GUser\") { name, fields { name }}}"} |
得到其所有字段:id, username, privateEmail。
再查询 id 为 1 的 admin 用户的 privateEmail 即可:
1 | { "query": "{ user(id: 1) { id, username, privateEmail }}" } |
Easy RSA
观察代码,我们有三个任务:
- 计算
p - 通过
value[-1]反推全部value - 通过
value_q反推q
1. 计算 p
查找资料,可以找到一个叫“威尔逊定理”的东西,即当 p 为质数的时候,有:
(p−2)!≡1(modp)
则:
y!≡(x−2)!×(x−2)!y!≡∏i=y+1x−2i1≡i=y+1∏x−2inv(i)(modx)
代码:
1 | def get_p(x, y): |
2. 反推 value
这个部分涉及到一个最主要的函数就是 sympy.nextprime,先看看它的文档:
def nextprime(n, ith = 1)
Return the ith prime greater than n.
See Also: prevprime: Return the largest prime smaller than n.
……我感觉官方文档都告诉你应该怎么做了。
1 | def get_first_value(last_value): |
3. 反推原始 q
这个部分就是给出这个式子(我们把这个原始的 q 称为 x):
q≡xe(modn)
已知 e, n, q,求 x。
然而我不会求,查资料,发现了这个:Finding the k-th root modulo m,简直完美。
按照这篇文章(回答)所说,首先求满足这一式子的 u, v:
ue−vφ(n)=1
显然 gcd(e,φ(n))=1,这一步可以用 exgcd 做。
求出来了之后,就有
u)e ( n)x≡(bu)e(modn)
写成代码,就是:
1 | # 这里的 n 我们通过 `first_value` 生成 |
经过验证,以上三个脚本算出的结果,代入进源程序中,都可以算出源码中对应的结果。
4. RSA 解密
RSA 解密还需要一个数 d(含义请自行翻看 RSA 文档,也可以看这篇)。
这个 d 需要满足以下式子:
ed≡1(modn)
在先进的 Python 3.8+ 中,可以直接用 pow(x, -1, mod) 来算逆元,省事不少。
于是解密部分的代码:
1 | pn = sympy.ntheory.factor_.totient._from_factors({ p: 1, q: 1 }) # phi(n) |
然后就可以拿到 flag 了。
加密的 U 盘
通过查询 LUKS 的使用文档,可以发现其可以使用密码或 keyfile 加密,于是大胆猜测改密码不会改变 keyfile 一类的东西(注:实际上是 master key 不会变)。
首先使用 losetup -P /dev/loop1 day1.img 将镜像挂载至 loopback(day2 同理)。
然后用 cryptsetup luksDump --dump-master-key /dev/loop1p1 dump 出 master key。MK dump 里就是 master key。并用 xxd 或其它工具将 master key 写入文件。
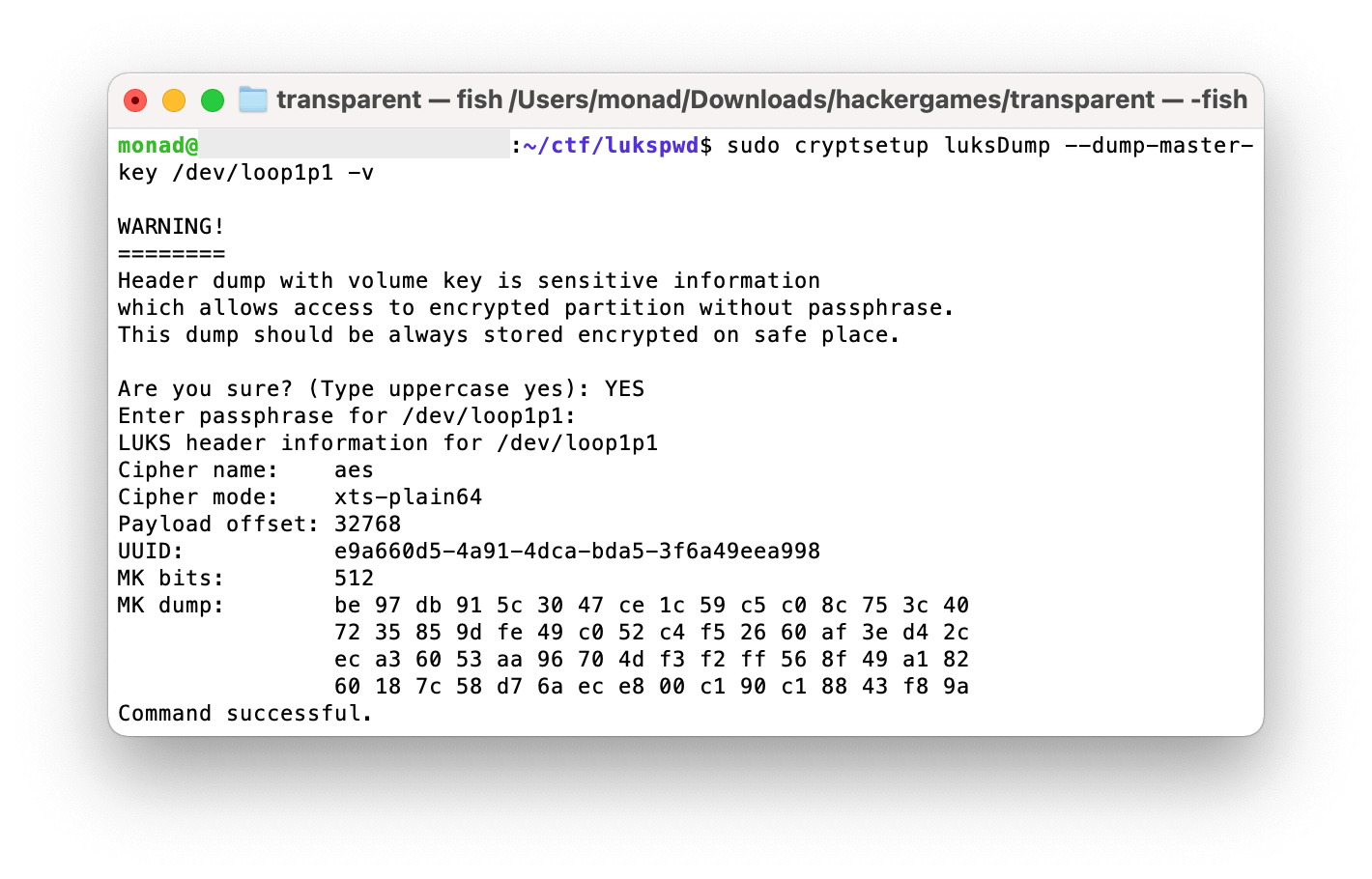
接着用 master key 打开 day2.img 即可:sudo cryptsetup luksOpen --master-key-file <key file> /dev/loop2p1 day2。
最后把 /dev/mapper/day2 mount 一下就能读出 flag.txt 了。
赛博厨房
Level 0
写 4 个程序,针对不同菜谱执行不同程序即可。
1 | 向右 x 步 |
自行修改 x, y = 1 or 2 来控制不同菜谱即可。
Level 1
写个简单循环,把物品不断放到锅中即可。
1 | 向右 1 步 |
Level 2
写 32 个程序,第 i 个程序分对应 [0, 0, 0, 0, 0, i] 这个菜谱。 然后再额外加一个程序,写 向右 {} 步,然后枚举数字,撞 hash(实际上是两个 sha256 和一个 arc4 随机?)。
暴力代码见:GitHub Gist 4febc8f。
灯,等灯等灯
Level 0
解一个线性方程组即可。代码过丑就不放了(逃)。
我发现我不会写 % 256 意义下的高斯消元,于是我就直接用 Python 高精度,解完再取模。
然后我解完之后,没有去研究提交的 HTTP API,直接就写了个程序模拟鼠标点击(逃)
Micro World
随便乱瞅一下(我不会告诉你我走了多少弯路的),能发现这个程序是用 pyinstaller 生成的。
然后就找一个 pyinstaller unpacker(我用的是 extremecoders-re/pyinstxtractor),然后就可以发现一个 2.pyc 文件。用 pip 安装 pygame 后,发现可以直接用 python 2.pyc 运行,能确定提取出了正确的东西。
接着继续尝试反编译,我这里找了 zrax/pycdc,能够逆向 Python 3.9 的字节码,但不完全能逆向出来(但是至少能看到大致的逻辑,也能看到点的数据)。
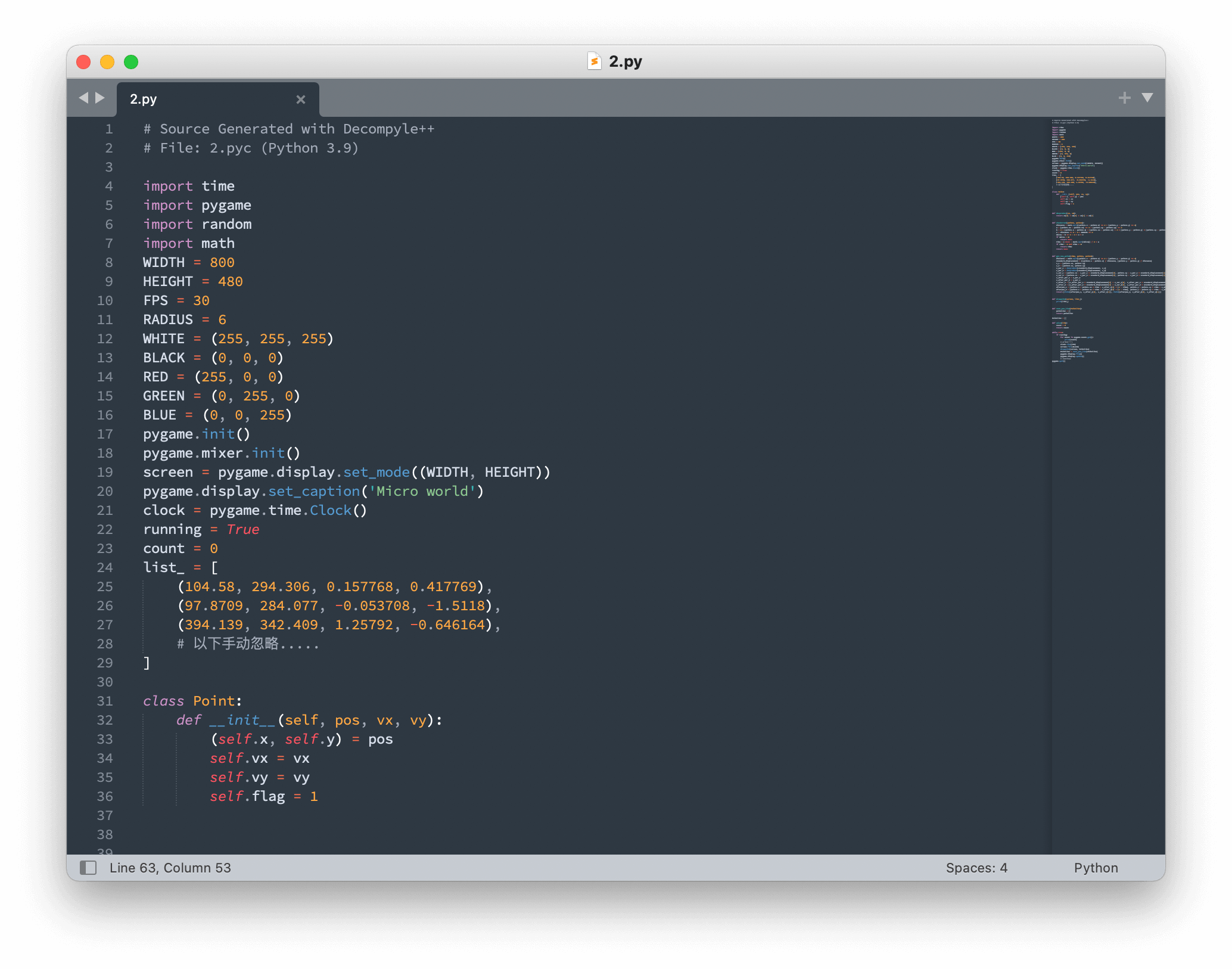
这是 2.pyc 中 Point 的定义:
1 | class Point: |
不难猜出,vx 和 vy 就是这个点的移动速度(也就是 list_ 每个元素的后两个值)。显然,只要把这个速度取相反数就可以还原出原 flag 图案了(显然碰撞是可逆的)。
然而我并不想对着 bytecode 翻译一遍代码,所以我决定动态“注入”到 2.pyc 里面改变量。下面我们先把 2.pyc 重命名成 w2.pyc,因为不能直接 import 2。
但是 import w2 后,import 没返回,窗口已经运行了,有点难改变量。下面开始乱搞!
我们可以新建一个 pygamx.py 来 mock pygame,然后修改 2.pyc 的 bytecode:暴力把 pygame 改成 pygamx(暴力替换二进制数据即可)。
pygamx.py:
1 | import pygame |
然后经过测试,可以在上面 pygame.time.Clock.tick 里面反向 import w2,修改 list_ 和 Pointlist,把速度取反,就可以了。
此时直接运行 python w2.pyc,并且在控制台窗口用回车控制每一帧,看到 flag 差不多展示出来了就行了:

阵列恢复大师
数据恢复软件都是浮云,手撕才是正道。
当时做题的时候,看着 RAID 5 通过的人比 RAID 0 多,所以就先跑去做 RAID 5 了。后来仔细思索一下,可能是因为 RAID 5 有软件能一键恢复吧。
1 - RAID 0
额,在恢复之前,先来看一下 RAID 0 的结构。

说白了大概就是按块大小分块,然后按顺序依次存放在各个盘中。所以一个推论就是,一段内容只会出现在一个盘里面。
为了方便起见,先把硬盘名字按照字母序重命名成 1~8.img。
先随便看看这些盘的内容,然后不难发现,8.img 的 0x00000200 处有一个 EFI PART,这是 GPT 分区表的标志。于是就不难推测出 8.img 是第一个盘。
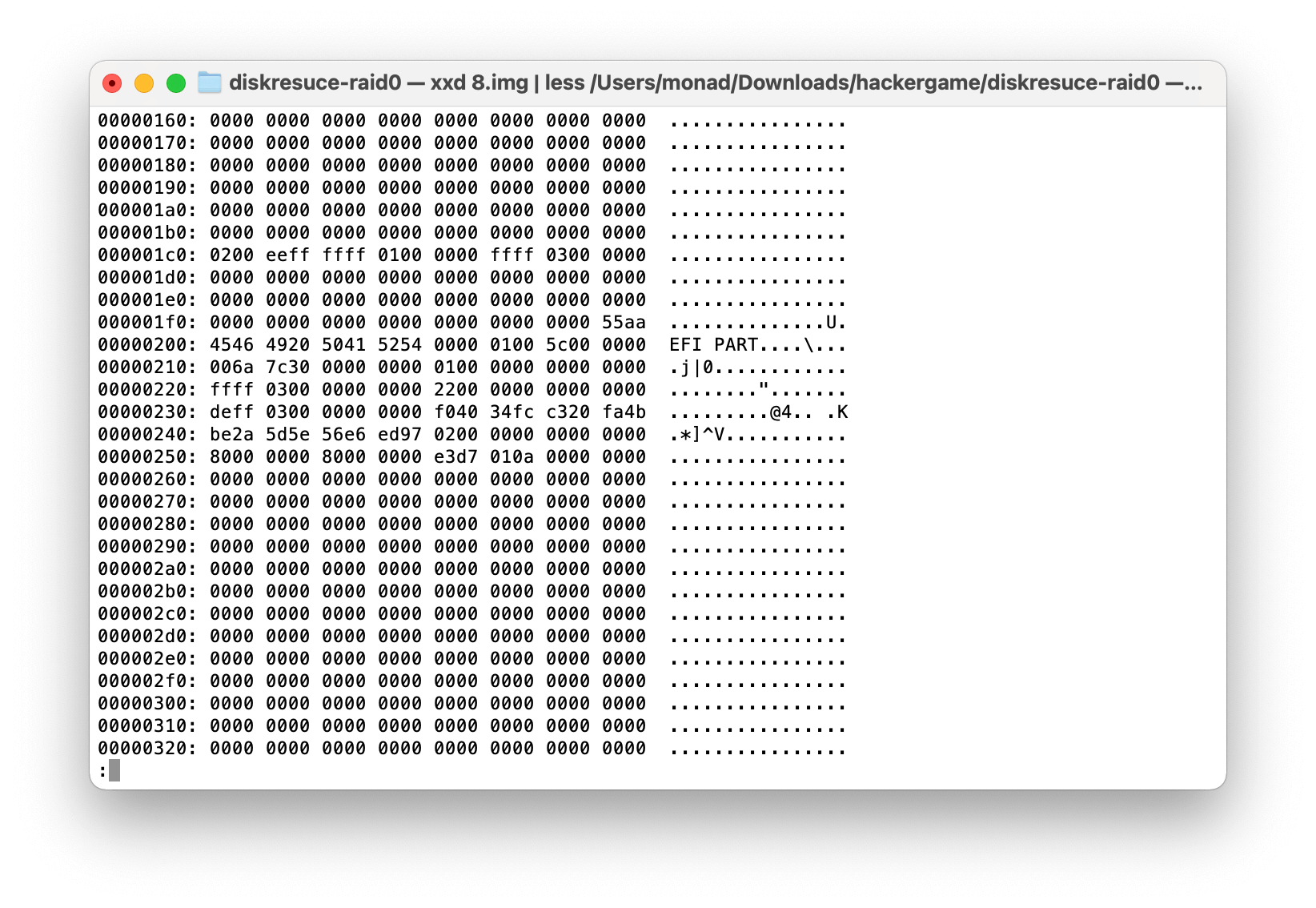
然后的话,再随便翻翻这些盘的内容,发现似乎空的部分(0x00)比较多。要确定盘的顺序的话,因为块与块之间是直接拼起来的,所以可以直接看内容的连续性来判断块的顺序,进而判断盘的顺序。
这样的话,随便翻看几下,发现 0x008C0000 和 0x008E0000 附近的内容有断层,而且丰富性比较高,有文本、乱码、零。并且从这两个“断层”的距离不难推测出块的大小是 128KB。(注意下面第 4 块盘的 0x008E0000 前的部分,n 后面应该有一个空格。)
| Disk | 0x008C0000 前 |
0x008C0000 后 |
0x008E0000 前 |
0x008E0000 后 |
|---|---|---|---|---|
| 1 | 0x00000000 | 2J..`...HD.....k |
Subtype /Link /R |
0x00000000 |
| 2 | 0x00000000 | ect [118.3625 23 |
g_system_respons |
0x00000000 |
| 3 | 0x00000000 | iveness_under_lo |
...:......b.<.dL |
0x00000000 |
| 4 | 0x00000000 | .q,.[.Q..B....Y. |
0470796 00000 n |
0x00000000 |
| 5 | 0 obj.<< /A 489 |
..g..b.c.D\...G. |
F.O...\i...o.G.. |
0x00000000 |
| 6 | 0x00000000 | 000 n .000007636 |
M.t.p...V+.,=.2. |
0x00000000 |
| 7 | 0x00000000 | .0000470505 0000 |
4....%......,.iI |
0x00000000 |
| 8 | 0x00000000 | 0 R /Border [ 0 |
n .0000076610 00 |
.0..TL$w.......1 |
根据 RAID 0 的结构,不难推测出 1 - 2,2 - 3,4 - 7,5 - 8,8 - 6(能分成三大块:5 8 6,1 2 3,4 7)。(如果觉得看表难推测的话,可以再看看这些位置的上下文,找一下文本的规律(常见词等)。)
到这里,可能的盘的顺序就只剩下 8 6 1 2 3 4 7 5 和 8 6 4 7 1 2 3 5 两种,已经很优了。如果懒的话,可以直接两种方法都试一下,看看哪种对的就行了。
实际上,在 0x001C0000 ~ 0x001E0000 的地方,可以观测到内容从有(非 0x00)变无(0x00):
| Disk | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Not 0x00? | T | partial | F | F | F | T | F | T |
据此,能推断出第 2 块盘在第 4 个位置。也就是说上面的两个方案,8 6 1 2 3 4 7 5 是对的。
既然顺序和块大小(128 KB)都有了,直接恢复出完整镜像(我用了一下 DiskGenius),然后把镜像挂载一下就行了。
2 - RAID 5
同理,先来看看 RAID 5 的结构。

与上面 RAID 0 不同的是,它多了一块奇偶校验块。
也像上面一样,先瞅瞅这些盘的头部。
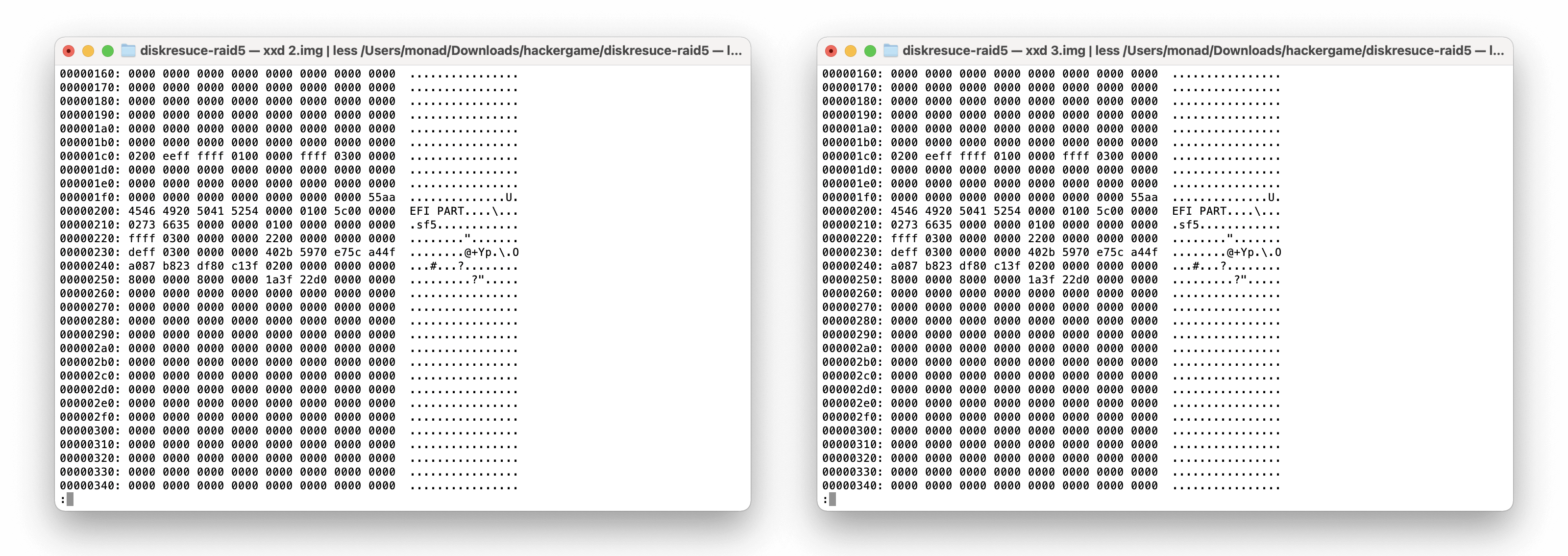
然后可以发现 2.img 和 3.img 有 GPT 头,故可以确定这两个盘一个是第一个位置,另一个是最后一个位置(首个校验块所在盘)。而且在 2.img 的 0x0040400 的地方可以找到 ext2/3/4 的 superblock。
所以现在就只剩下 12 种方案了……这一次我比较懒,就没有继续了(而且也懒得分析比较复杂的 RAID 5 了)。
然后我真的就去莽了,块大小 64 KB 和 256 KB 都莽一下(不要问我为什么不试 128 KB),再把上面 12 种方案都过一遍。实际操作就是在 DiskGenius 上排顺序,看看那个拼好了之后,DiskGenuis 能找到 ext2/3/4 分区。
最后试了几下,试出来了 2 4 1 5 3(块大小忘了实际上是多少了),然后用 DiskGenius 导出镜像(不知道为啥我那玩意不支持导出大于 1 MB 的文件),然后瞎搞一下,mount 上了就行了。
为什么我导出镜像之后还要用 testdisk 找一下分区后,导出分区才能挂载。
助记词
说句实话,这道题一点也不 math。
第一顿大餐
下载程序源码,打开。
其中 cn.edu.ustc.lug.hack.mnemonic_phrase.Instance 里的 post 是主要逻辑(flag 的处理也在这里),并且不难发现,这个函数里面有一个 for 循环,调试一下,发现每次请求好像只会循环一次。
回头看 HTTP API,发现似乎可以一次性提交一个数组,尝试一下提交 32 个相同的助记词,然后发现正好可以拿到第一个 flag。
第二顿大餐
作为一个逆向过 Minecraft 种子生成的人,怎么会止步于此呢
观察发现,sleep 函数是在 Phrase.equals 方法中执行的,然后我们并没有在本项目中发现直接调用它的地方。
再思考一下,能发现它会在 Set<Phrase>(实际上是 LinkedHashSet)中被 Set 调用。
第二个 flag 需要卡顿 9 秒,掐指一算,大概需要调用 equals 450 次,大概是 n2 的级别。
查看 ,猜测一下,我们要构造 LinkedHashSet 源代码hash 相同的 Phrase,让 Set 进行 n2 级别次数的比较。
然后看 Phrase.hash 方法:
1 |
|
再看 Object.hash 方法:
1 | public static int hash(Object... values) { |
1 | public static int hashCode(Object a[]) { |
换句话说,就是分别对 this.text, this.time, this.user 分别调用 .hashCode(),然后再拼在一起。这里先看 this.text(即 String)的 hashCode。
1 | public int hashCode() { |
这个函数就是首先做了一个缓存,如果 hash(String 的一个 field)存在,就不算了。主要逻辑在 for 循环上。
我们可以把这个算法提取出来,暴力算 6004 种 hash(其实也可以双向 BFS,我这里没用)。
下面的暴力代码用 Rust 写,并且进行了一点小优化(因为算 hashCode 的过程是线性的),大概 5 分钟能跑完全部 6004 种 hash:
1 | use std::collections::HashMap; |
上面的程序只会输出 hashCode 对应的单词的序号。
再写个程序解析这个输出(把两个程序分开,进行下面的操作的时候就不用重复破解 hash):
1 | s = [ ... ] # 单词表 |
但是直接把暴力出的结果扔进程序里,发现最多只能卡 3 秒左右,是怎么回事?
我们继续看回去那个加单词的循环,把每一次循环所需的时间输出,就可以发现它的时间是 24 - 49 - 71 - 103 - ... - 254 - 0 - 24 - 47 - ... - 243 - 0 - 23 - ...(数字不是复制的,但是趋势是一样的)。
Phrase.hash 是 Objects.hash(this.text, this.time, this.user);,每过一秒,this.time 的变化就会使我们精心构造的 hash 冲突给毁掉。
这个有点难处理,观察回 Arrays.hashCode,我们可以把 this.text.hashCode * 31 后的 hash 缓存起来,每次当 this.time 加一的时候,我们就让 this.text.hashCode * 31 减一。
至于在这个长度为 32 的序列中,应该什么时候减一的这个问题,我也没有好的思路,只是随便试,试了一个相对较好的:
1 | d = [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9 ] |
由于实际运行时的微妙时间差(即开始运行的时候,并不是完全正对着每秒的开头的),所以要在在线的网站上多试几次。
马赛克
这道题的简单题意就是,给你一个打了码的二维码,并且给出打码的程序(算法是模糊部分的一个大的 block 的颜色,是这个区域内颜色的平均值)。简单算一下信息量,感觉还是能复原的。
一些用词(为了避免混乱所以先说明):二维码的块:指模糊前的二维码的一个黑白块;码的块:指打码部分的一个色块(应该没毛病吧)。
于是乎,最朴素的方法就是……枚举原二维码每个块的黑白,然后看看跟模糊后的是否一致,但是这样做时间成本太大了。
然后可以发现,这个码的一个块的影响范围是有限的,大概就 10 个左右的二维码块。于是我们就可以针对每个码的块,枚举其下的二维码的黑白。再把每一个块的有效方案拼起来即可。
原理听懂了吗?原理大概就这个样子。但是……你发现这个确实并不好实现(大概?)
具体实现的话,假设前面处理了若干个块,这些块拼在一起的有效方案(可能有多个)放在一个数组 p 里。然后处理一个新的块的时候,就把当前区域的方案,与 p 中的匹配(能相容的就结合),把新的方案放到一个新的数组 q 供下一轮使用。
具体代码(调试输出十分炫酷,建议运行):
1 | import random |
minecRaft
打开网页,我们发现了一个微型 Minecraft 游戏,然后就开始愉快的摸起鱼来。
咳咳,这是一道 web 题,并且「本题解法与原版 Minecraft 游戏无关」。故 F12 打开,然后可以看到 html 内嵌的 js 中有这么一段:
1 | if (cinput.length >= 32) { |
并且 gyflagh 这个函数是定义在 flag.js 里面的,很难不猜测这就是最终涉及到 flag 的地方。
打开 flag.js,然后我们看到了一堆乱码…………
首先我们可以把 0x 打头的十六进制数转成十进制数,不然的话跟变量的命名很像,看着太瞎眼了。
然后观察一下参数是 422 到 439 之类的函数,可以发现都跟一个叫 _0x2c9e 的函数有关。
把这个 js 贴到 Devtools Console 里面,多执行几次,发现返回值不会变,并且都是 charCodeAt,slice, fromCharCode 这种函数名,不妨可以猜测这个函数只是一个 string mapping。所以我们就把这个 mapping 手动给它转回去。
替换完了之后,应该就只剩下变量名比较难看了。所以根据上下文,给这些变量换个名字。
这波操作下来之后,这个代码就好看了不少:
1 | String.prototype.encrypt = function(key_str) { |
我们先把目光放在 String.prototype.encrypt 上,这个函数首先将 key_str 分成了 4 段(1356 8531 4905 4377),然后将每一段通过 Str4ToLong 转为整数。
接着,再把 text(64 个字符,每 8 个分一段)分成 4 段,每一段中再分成前后两个部分(不妨称为 a, b),然后把 a, b 扔给 code 做变换,再把变换后的 a, b LongToBase16 后加到 result(字符串)后面。
上面这段话可能有点难理解,拿 gyflagh 中的例子来说,假设 text = "mInecRaft#-ls_900d_f0r_$ntEr1ain",就是:
1 | Str4ToLong code LongToBase16 |
但是实际上,text 是什么我们是不知道的,我们要用 encrypted 来反推 text,其关键显然在 code 这个函数中。
然后现在的话,我们要完成的目标就是(右边的数值可以用 encrypted 进行 Base16ToLong 得到):
1 | code([?, ?], key) -> 1874716276 -2120590913 |
然后我们可以注意到,code 函数的计算是可逆的,可以通过最终的结果反推出输入的值。
于是随便写一个逆向程序:
1 | const KEYS: [Wrapping<u32>; 4] = [ Wrapping(909456177), Wrapping(825439544), Wrapping(892352820), Wrapping(926364468) ]; |
然后就不难推算出 code 的输入是:
1 | [ 1700225869, 1598378594 ] |
然后再把这些值用 LongToStr4 拼回去,得到 McWebRE_inMlnCrA1t_3a5y_1cIuop9i。
密码生成器
运行密码生成器,发现并没有输入栏;并且能够感觉到,这道题是要“复现”输出。
然后,我们可以盲猜……这个程序的“输入”是,时间,精度大约是 1 秒。
然后的话,我们就可以把时间设置成 2021-09-22 23:11(也可以用 RunAsDate)(感觉那个时区只是一个障眼法),然后生成一些密码,多试几个,就成了。
密码是 $Z=CBDL7TjHu~mEX,登入就能获取 flag 了。
顺带一说,为了更方便手操(cao 一声),我还弄了一个自动读剪贴板的东西,这样鼠标就只用点“生成”、“复制到剪贴板”了。
1 | import win32clipboard |
JUST BE FUN
写在前面:这道题有更好的解法,甚至可以两维完成。我这里的话,首先是当时也没想那么多,基本上是“能跑就行”,其次我以为交换只能交换栈顶两个数,这个就限制了很多可能。所以这个解法看个乐就行。
说实话,这道题还是蛮有意思的。怎么说呢,看着自己写的指令在三维空间上执行,虽然实际上没有什么用,但是看起来炫酷就完事了。
这道题的大致意思就是,你可以在一个三维(256 * 256 * 256)的空间(可以看成是地址)上写程序(每个点能写一个指令),然后解析器会在上面跑。同时解析器会随机生成一个求值字符串,需要你编写一个能正确算出这个值的程序。
| 指令 | 机器码 | 读取数 | 写入数 | 含义 |
|---|---|---|---|---|
| ADD_OP | + |
2 | 1 | 将栈顶两个数相加 |
| SUB_OP | - |
2 | 1 | 将栈顶两个数相减(栈顶为减数) |
| MUL_OP | * |
2 | 1 | 将栈顶两个数相乘 |
| DIV_OP | / |
2 | 1 | 将栈顶两个数相除(栈顶为除数) |
| MOD_OP | % |
2 | 1 | 将栈顶两个数取模(栈顶为模数) |
| NOT_OP | ! |
1 | 1 | 取非 |
| CMP_OP | ` |
2 | 1 | 比较,栈顶小则 1,否则为 0 |
| X_U_OP | > |
0 | 0 | 向 x+ 运行 |
| X_D_OP | < |
0 | 0 | 向 x- 运行 |
| Y_U_OP | v |
0 | 0 | 向 y+ 运行 |
| Y_D_OP | ^ |
0 | 0 | 向 y- 运行 |
| Z_U_OP | [ |
0 | 0 | 向 z+ 运行 |
| Z_D_OP | ] |
0 | 0 | 向 z- 运行 |
| X_JMP | _ |
1 | 0 | 若栈顶为 True,则向 x- 运行,反之亦然 |
| Y_JMP | | |
1 | 0 | 若栈顶为 True,则向 y- 运行,反之亦然 |
| Z_JMP | # |
1 | 0 | 若栈顶为 True,则向 z- 运行,反之亦然 |
| STR_OP | " |
0 | n | 将此处(不含 ")到下一个 " 之前的指令,都作为 ASCII 写入栈中 |
| DUP_OP | : |
1 | 2 | 将栈顶元素复制多一份 |
| SWAP_OP | \ |
2 | 0 | 将两个指定位置的值交换(位置为相对于栈顶,不计这两个操作数,从 1 开始) |
| POP_OP | $ |
1 | 0 | 弹出栈顶一个元素 |
| NUM_OP | . |
1 | 0 | 将栈顶作为数字写入 result |
| CHR_OP | , |
1 | 0 | 将栈顶作为 ASCII 写入 result |
| INP_OP | ~ |
0 | 1 | 读取 input 序列的下一个字符,为 ASCII 码 |
| END_OP | @ |
程序结束 | ||
| NOP_OP | |
0 | 0 | 什么都不做(按照惯性继续向前) |
并且已知程序从 [0, 0, 0] 开始执行,方向为 [1, 0, 0](x+)。
输入序列是像 6*2|2*4<2*6*1x7^4|3 一类的字符串,运算符没有优先级(都是从左向右),数字都是 1 位数字。运算符具体含义如下:
| 运算符 | ASCII | 含义 |
|---|---|---|
+ |
43 | 加法 |
* |
42 | 乘法 |
^ |
94 | 幂运算 |
x |
120 | 二进制异或(XOR) |
| |
124 | 二进制或(OR) |
< |
60 | 二进制左移 |
于是我们可以大致确定这个程序的框架:
- 先获取第一个数字,压入栈中,作为初始数值;
- 获取下一个输入(运算符),然后分发到不同的代码段中执行;
- 重复第 2 个操作,直到遇到
\0。
于是我们可以设计这么一种 layout:
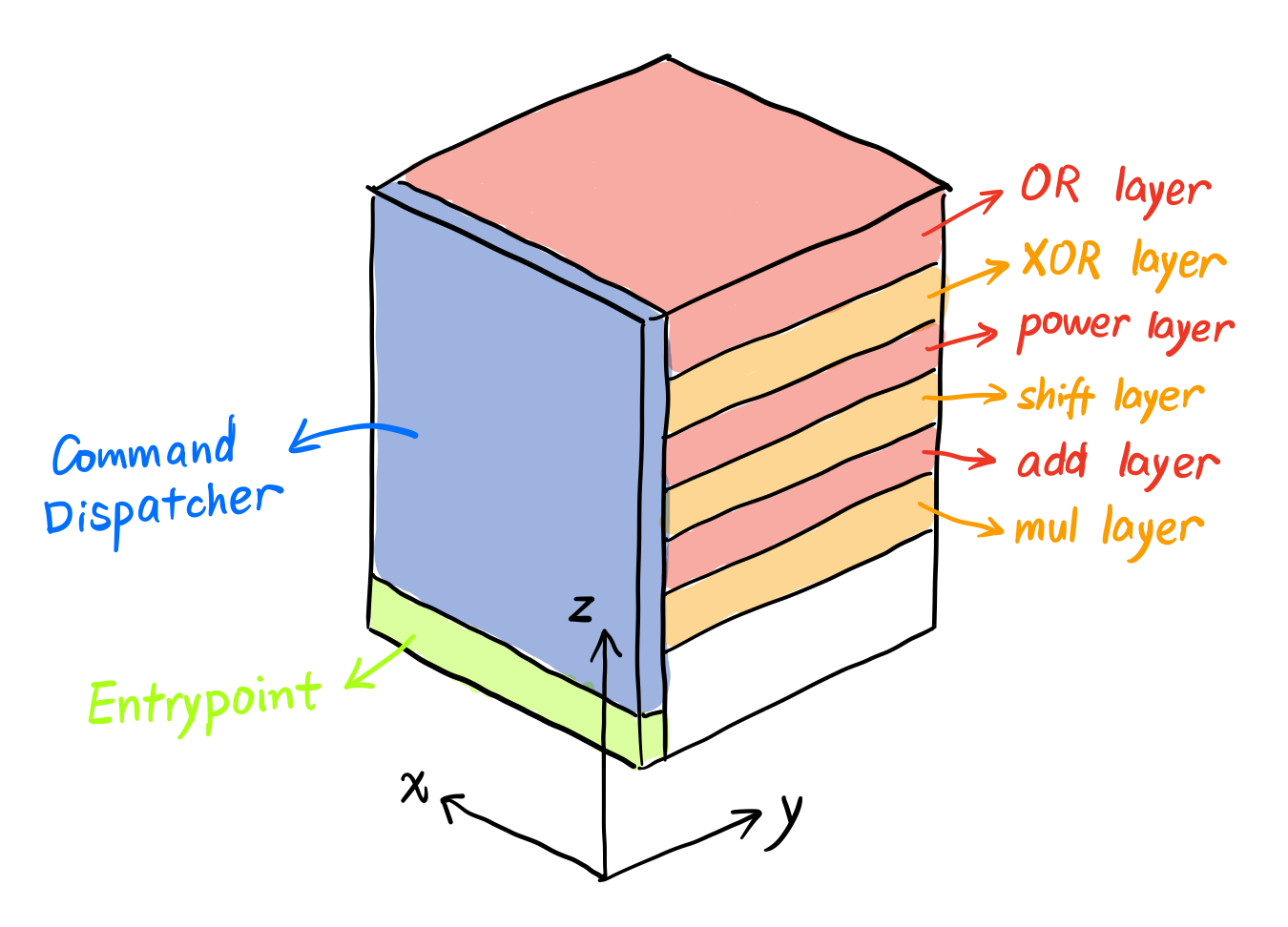
注意到运算符的顺序,按照 ASCII 来排序可以方便后面的比较操作(只需要比较 > 一次就可以了,不用反过来再比一次)。
至于每一层,反正它给了 256 格高,我直接给每一层分配了 16 格的高度,让它们自由发挥,避免上下冲突。
下面我们来分别设计这些部分,目录:
- Useful Patterns (Pre-requisite knowledge)
- Program Entrypoint
- Command Dispatcher & Returner
- Binocular Operator (Add, Multiple)
- Power and Shift Operator
- Bitwise Operator (XOR, OR)
Useful Patterns
在开始之前,我们先定义一些常用操作的 patterns。
比较栈顶位置与一个常数(0~9)
| 指令 | 栈 | 备注 |
|---|---|---|
[ val ] |
||
| DUP_OP | [ val, val ] |
栈顶元素需要保留,而比较指令会消耗参数,故复制一份 |
| 0~9 | [ val, val, 0~9 ] |
需要比较的常数 |
| CMP_OP | [ val, 0/1 ] |
进行比较,并且把比较结果放到栈顶 |
| ... | [ val ] |
自定义跳转 |
| POP_OP | [] |
如果整个匹配过程结束(val 不再需要) |
比较栈顶位置与一个常数(超出 0~9)
如果范围超出了 0~9,就要考虑用字符串模式将比较常数压入栈中。
| 指令 | 栈 | 备注 |
|---|---|---|
[ val ] |
||
| DUP_OP | [ val, val ] |
栈顶元素需要保留,而比较指令会消耗参数,故复制一份 |
| STR_OP | [ val, val ] |
进入字符串模式 |
| x | [ val, val, 'x' ] |
需要比较的常数(比 9 大的数可以找 ASCII 后面的字母) |
| 0 | [ val, val, 'x', '0' ] |
用来后面做减法 |
| STR_OP | [ val, val, 'x', '0' ] |
退出字符串模式 |
| SUB_OP | [ val, val, x ] |
减一下,获得真实数字 |
| CMP_OP | [ val, 0/1 ] |
进行比较,并且把比较结果放到栈顶 |
| ... | [ val ] |
自定义跳转 |
| POP_OP | [] |
如果整个匹配过程结束(val 不再需要) |
比较栈顶位置与一个字符
跟上一个相比,不用压入 0 了。
| 指令 | 栈 | 备注 |
|---|---|---|
[ val ] |
||
| DUP_OP | [ val, val ] |
栈顶元素需要保留,而比较指令会消耗参数,故复制一份 |
| STR_OP | [ val, val ] |
进入字符串模式 |
| x | [ val, val, 'x' ] |
需要比较的字符 |
| STR_OP | [ val, val, 'x' ] |
退出字符串模式 |
| CMP_OP | [ val, 0/1 ] |
进行比较,并且把比较结果放到栈顶 |
| ... | [ val ] |
自定义跳转 |
| POP_OP | [] |
如果整个匹配过程结束(val 不再需要) |
交换栈顶两个元素
因为我一开始以为只能交换栈顶两个元素,等到实现到最后才发现不是。反正无伤大雅,加两个操作数就完事了。
| 指令 | 栈 | 备注 |
|---|---|---|
[ v1, v2 ] |
||
| 1 | [ v1, v2, 1 ] |
|
| 2 | [ v1, v2, 1, 2 ] |
|
| CMP_OP | [ v2, v1 ] |
观察 be_fun.py 代码,易得 |
Program Entrypoint
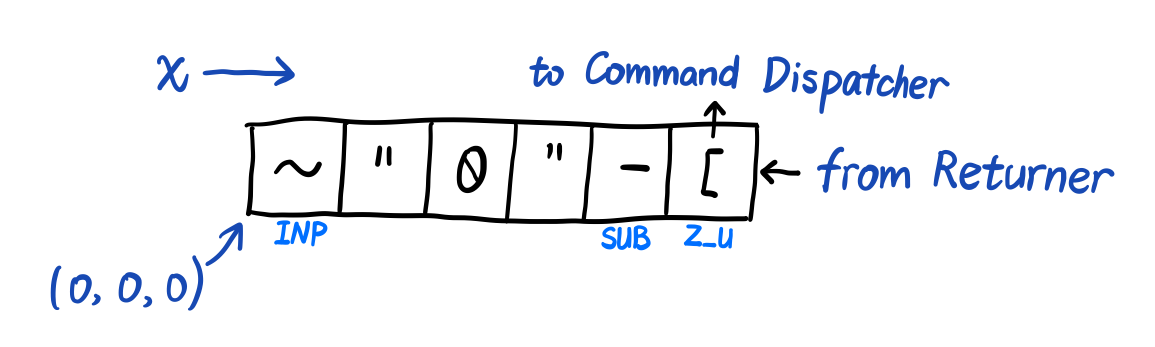
如图所示,获取第一个数字然后减去 0,然后向上跳转,将控制权交给 Dispatcher。
注意到这里还有一个 Returner,其实只是复用了一下这个 [ 字符,将 [ 看成两部分共用的即可。
Command Dispatcher & Returner
这一 section 的指令全部都是放在
y=0中。
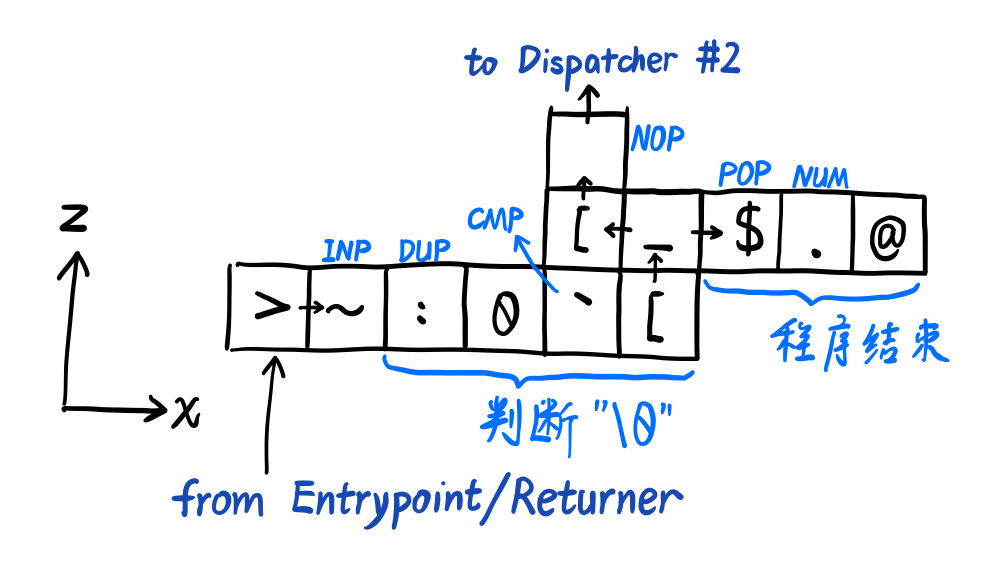
左下角的地址,可以看作是新一轮运算执行的开始(后面 Returner 也会返回到这个位置)。
所以先获取这一轮的运算符,然后判断是不是 0,是 0 的话就写出结果,然后退出程序。
否则就向 z+ 运行,到对应 Command 的 layer 的时候,就比较一下运算符,比较成功就跳转进去(y+)。
比较器如下所示,其中 +*^<|x 为这一层的 Command,根据情况安排:
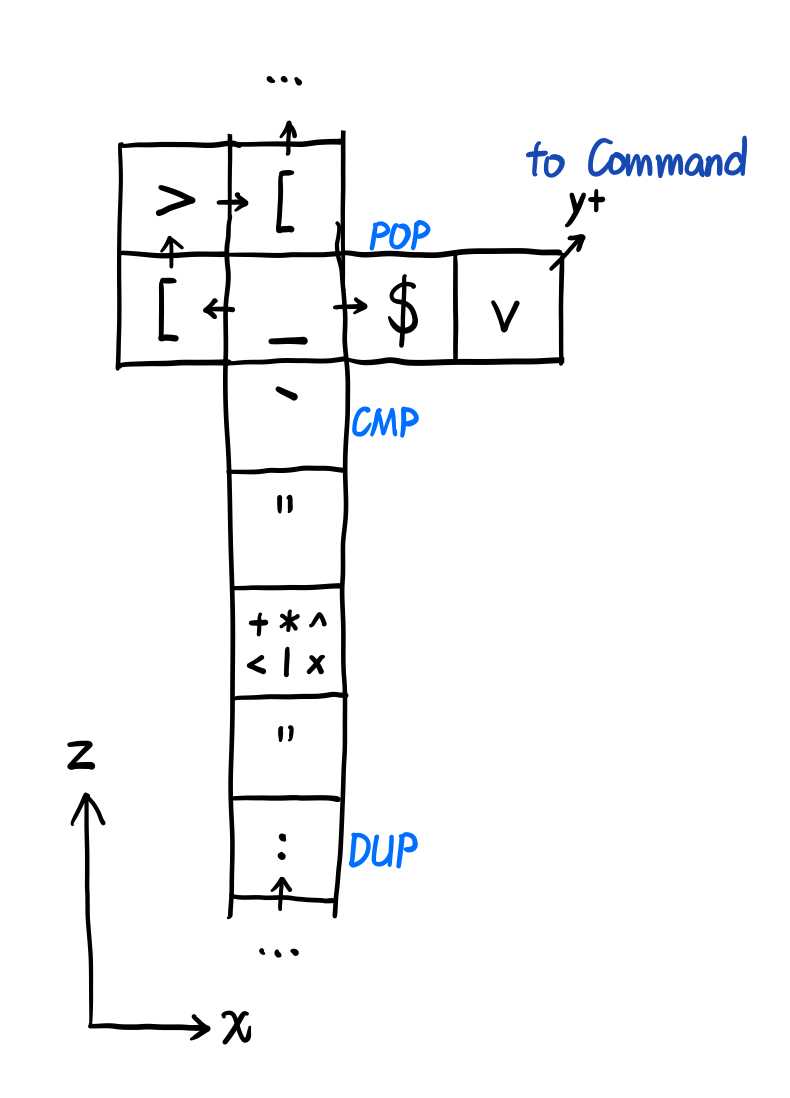
至于 Returner 的话,我就直接在 x=245, y=0 的地方安排一条 Z_D_OP 的返回通道,指令运行完就跳到这个位置就行。
然后在 z=0, y=0 的地方,再安排一条返回 [5, 0, 0] 的 X_D_OP 通道(返回到 Entrypoint 的 from Returner 的地方,然后进入下一轮运算)
其实这个怎么搞也没有太大关系,先把标准弄好,后面对接的时候就会比较方便。
Binocular Operator
加法和乘法比较简单,甚至指令都是一维的,就不画图了。
| 指令 | 栈 | 备注 |
|---|---|---|
[ val ] |
注意到运算符已经被提前 POP 出去了 | |
| INP_OP | [ val, 'x' ] |
获取运算数 |
| STR_OP | [ val, 'x' ] |
进入字符串模式 |
| 0 | [ val, 'x', '0' ] |
|
| STR_OP | [ val, 'x', '0' ] |
退出字符串模式 |
| SUB_OP | [ val, x ] |
因为前面的 x 是字符,需要减一个 0 |
+ or * |
[ res ] |
进行加法/乘法操作 |
这堆操作搞完了之后,就直接导航到 x=245, y=0 处就不用管了(控制权交给 Returner)。
Power and Shift Operator
这一段的操作主要是左移和幂。思考一下,虽然可以写一个简单循环,但是仔细想一下,发现细节还是挺多的,于是我就换了一个思路。
考虑到操作数只有 1 到 9 的范围,所以可以把这些把这些情况分开考虑(分别安排电路)。
对于左移操作,如果要左移 x 位的话,等价于乘上 x 个 2,于是我们就可以先压入 x 个 2,再执行 x 次乘法操作。
对于幂运算,就是把当前的 val 复制出 x 份,然后再执行 x - 1 次乘法即可。
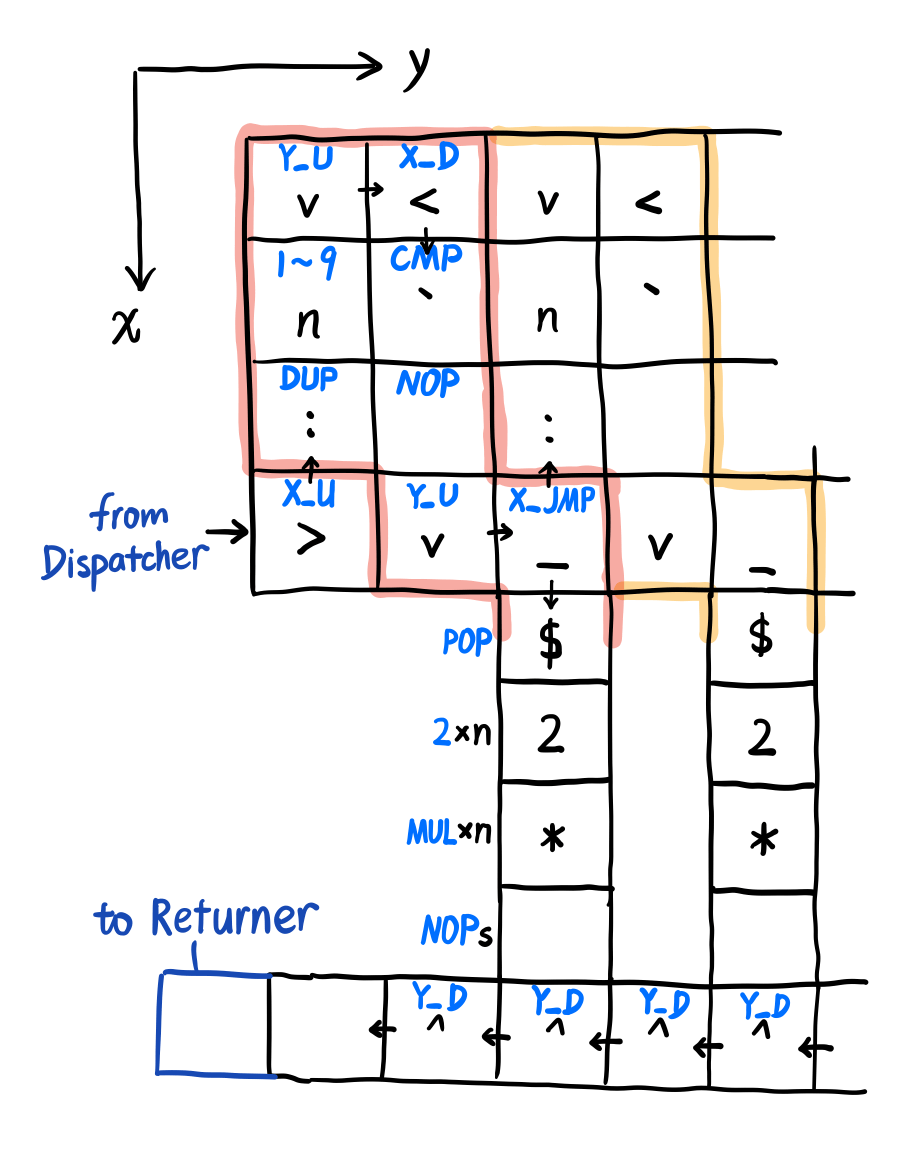
上面划出来点部分可以往后堆叠,我本来想做成单片的,但是没做成。注意到这里的 n 是从小到大(即 1~9)排的。
对于幂操作也类似,在中间竖条的地方改成 DUP_OP 和 MUL_OP(都是 x - 1 次)即可。
Bitwise Operator
这个位运算,我一开始在想,怎么用加减乘除模这些运算凑出来一个位运算啊。然后想不出来(也可能是我太菜了)。
如果不能凑的话,考虑到操作数只有 1~9,最多就是二进制的低 4 位,也就是说,对于左操作数,只用考虑它的低 4 位就行了(0~15)。
然后掐指一算,9×16=144,感觉打个表完全可以接受啊,整个地址空间每维有 256 个长度,完全够用。
也就是说,我们首先要把左操作数的低 4 位提取出来,跟右操作数一起寻址(打表)(实际上为了方便起见,这两个部分分开寻址),然后找到结果之后再跟原数的高位结合,就可以了。
先把大框架搭起来,先把左操作数 val 拆成 16a+b 的形式(为了可读性,这里省略掉一些重复的部分):
| 指令 | 栈 | 备注 |
|---|---|---|
[ val ] |
||
| DUP_OP | [ val, val ] |
复制一份,毕竟要拆成两个数 |
| STR_OP | [ val, val ] |
进入字符串模式 |
| '0' + 16 | [ val, val, '@' ] |
因为 16 超出了 0~9,只能这样干了 |
| '0' | [ val, val, '@', '0' ] |
|
| STR_OP | [ val, val, '@', '0' ] |
退出字符串模式 |
| SUB_OP | [ val, val, 16 ] |
减一下,获得真正的 16 |
| DIV_OP | [ val, a ] |
除一下,获得 a |
| 1, 2, SWAP_OP | [ a, val ] |
交换栈顶俩元素 |
| STR_OP | [ a, val ] |
|
| * | [ a, val, 16 ] |
自行用 STR 压入 16(参考上面) |
| MOD_OP | [ a, b ] |
模一下,获得 b |
| ... (P1) | [ a ] |
把 b 拿去匹配(寻址) |
| INP_OP | [ a, 'x' ] |
|
| * | [ a, x ] |
自行减 0 |
| ... (P2) | [ a ] |
把 x 拿去匹配 |
| STR_OP | [ a ] |
|
| '0' + r | [ a, 'r' ] |
打表结果 |
| '0' | [ a, 'r', '0' ] |
|
| STR_OP | [ a, 'r', '0' ] |
|
| SUB_OP | [ a, r ] |
|
| ... | 这里可以先返回,后面的内容可以复用 | |
| 1, 2, SWAP_OP | [ r, a ] |
|
| * | [ r, a, 16 ] |
自行用 STR 压入 16(参考上面) |
| MUL_OP | [ r, a * 16 ] |
|
| ADD_OP | [ a * 16 + r ] |
然后把子 dispatcher(P1、P2)写好就行了。由于打表,2 个变量就要用掉 2 维,还有一维要放匹配完后执行的指令,所以以下三维灵魂抽象画警告。
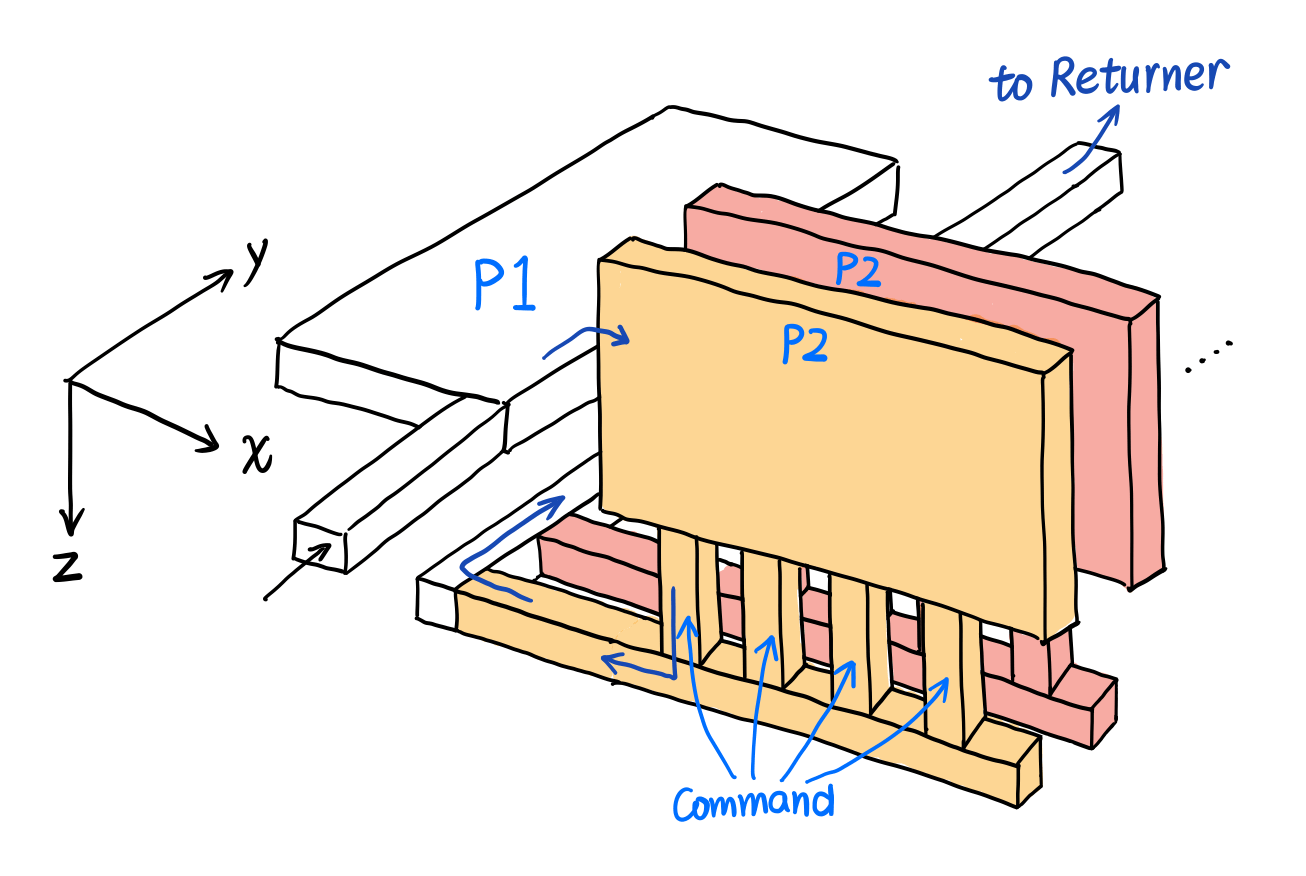
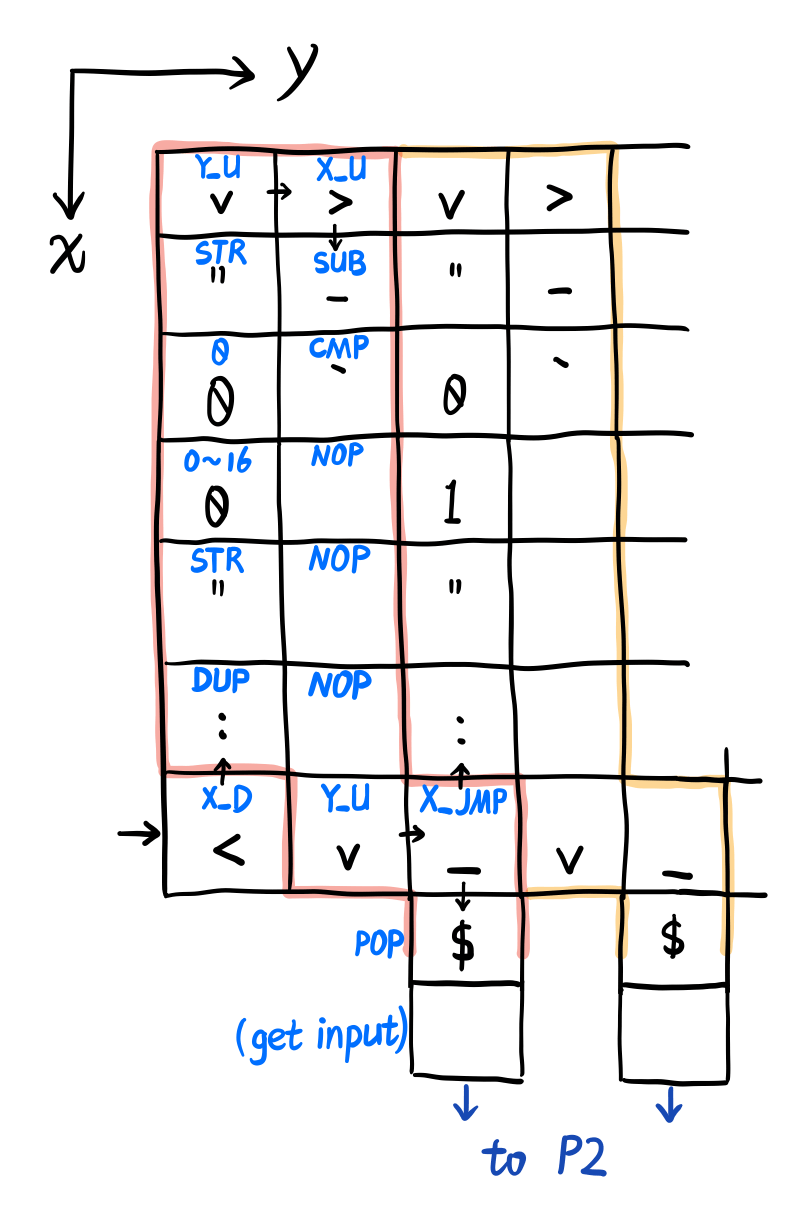
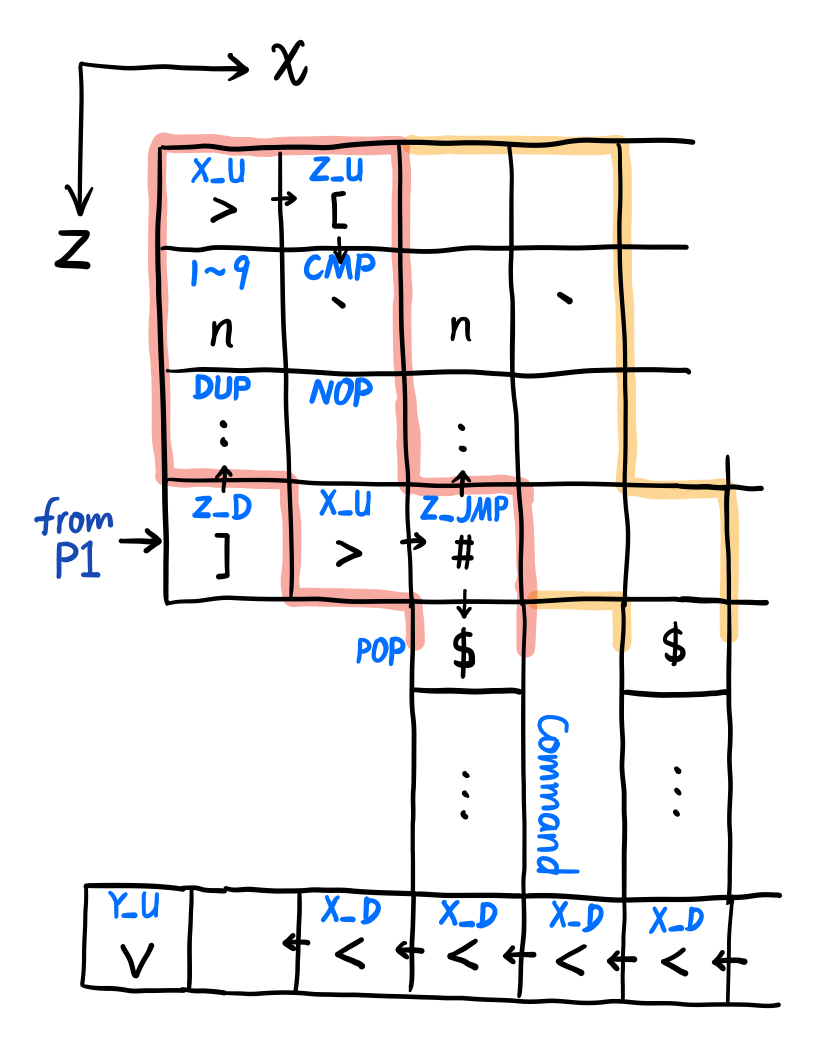
大概就是这个样子,相信大家都能看懂吧()。
最后把所有的部分拼起来,就成了。代码呢,就是这个样子:
1 | from pwn import * |
p😭q
这道题本质上就是如何用眼看音乐,是把频谱图转换为声波。
我本来以为这道题还要手撕 FFT 的,结果发现完全不用,首先给了代码,再者[见下文],于是这道题就完全是一道工程题,只要会调库就可以了。
看源码,源码大致可以分成两个部分:正向 FFT,和 gif 生成。
我们就反过来“逆向”每一步就行了。
首先是读 gif,这个没啥好说的,只是细节比较多,直接上代码(趴):
1 | image = Image.open('flag.gif') |
随后就是要逆向这个 melspectrogram。看源代码:
1 | spectrogram = ( |
最外层,/ quantize, numpy.around, * quantize 就是将 dB 取整。
然后再里面一层,就是 librosa.power_to_db,看这个命名……盲猜一下……大概有个函数……可以把它反过来,还真有:librosa.db_to_power。
再里面一层,就是 FFT 大头,librosa.feature.melspectrogram,本来呢,我还做好准备要手撕 FFT 的,然后一查文档,发现好家伙,这函数也有逆函数 librosa.feature.inverse.mel_to_audio,这就省事了。
接下来的事就是把上面的过程反过来套一遍就可以了:
1 | db_frames = [ ... ] # 上面的 db_frames |
至此,我们就把 gif 逆向成了 origin.wav。
音频是「The flag is, F-L-A-G, 634,971,243,582」(数字是英语数字的读法)。